Understanding Infrastructure-as-Deployed
Engineering teams are steadily adopting a “cattle, not pets” attitude towards infrastructure. Cloud providers are enabling easy-on, easy-off services. As a result, churn in production deployments has become a fact of life. Engineers have begun to apply the tools of the trade to this problem: infrastructure-as-code (IaC) tools such as Terraform and CloudFormation allow practitioners to express their desired state of the world. Because IaC fits into the paradigm of source code, the same supporting tools are available: IDEs, code review, continuous integration, and continuous delivery. This movement towards structure is helping teams to effectively take advantage of the benefits of the cloud at larger and larger scales.

Describing how your infrastructure should be deployed is, however, only a piece of the puzzle. As companies grow, it becomes more and more important to also understand Infrastructure-as-Deployed.
Infrastructure-as-Deployed is what is actually running, regardless of what you intended to run. And this is where the constant flux can bite you.
So how can we tame this churn? Just as we did with expressing our intent, we can use the tools of the trade. In this case, the relational database. Infrastructure-as-Deployed is snapshotted (via Introspector or other tools) and made available for querying via SQL. Much like IaC enables code review of infrastructure changes, cloud deployments in a database enable the whole universe of existing analysis tools that speak SQL. We can leverage those to replace sampling for compliance with certainty.
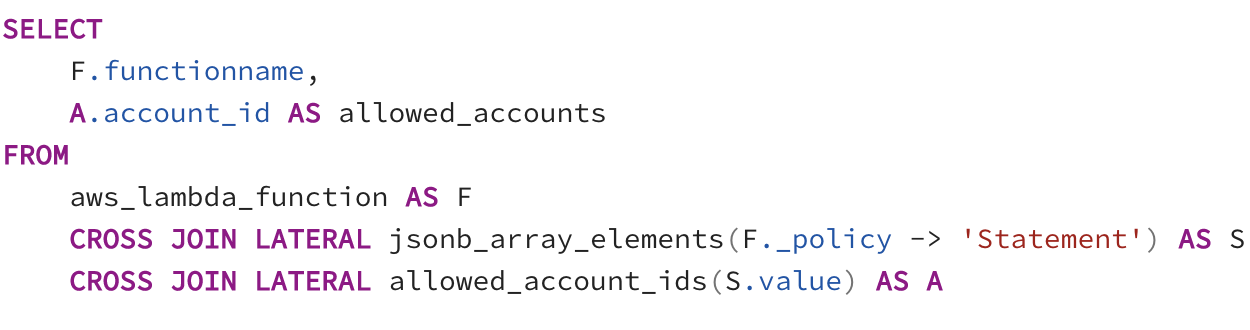
But what about the data model? Cloud infrastructure configurations are both relational and graph-based in nature. Network interfaces have a many-to-many relationship with Security Groups, for instance, while the question of which principals have a particular permission involves traversing a graph of groups and policy attachments. Modern databases allow both paradigms to coexist and intermingle, even in the same query. In particular, recursive common table expressions allow traversing graph relationships in a SQL context, with the ability to apply traditional relational algebra at any point in the process.
This power of expression enables writing complex regulatory policies in a way that can be answered by a database engine (see an example assessing AWS Resource Policies here), replacing what was previously a manual assessment. Furthermore, once you pull in multiple data sources, the questions you can ask escape single provider APIs. Pull in your version control provider and query for every unreviewed line of code running in a particular container. Or pull in your org chart, and find out who outside the engineering department has access to an S3 bucket. Using SQL lets you explore your infrastructure-as-deployed with the tools you are already familiar with.